2025–2026 Google AI 搜索排名公式
一、AI搜索排名系统的整体结构
在传统搜索中,排名流程是:
Query↓Index Retrieval↓Ranking↓SERP在 […]

在传统搜索中,排名流程是:
Query↓Index Retrieval↓Ranking↓SERP在 […]
AI Overview 的来源选择通常可以简化为:
Query
[...]
AI搜索并不是一个新搜索引擎。
实际上它是在原有搜索上加了一层:
User Query
↓
Query Understanding
[...]
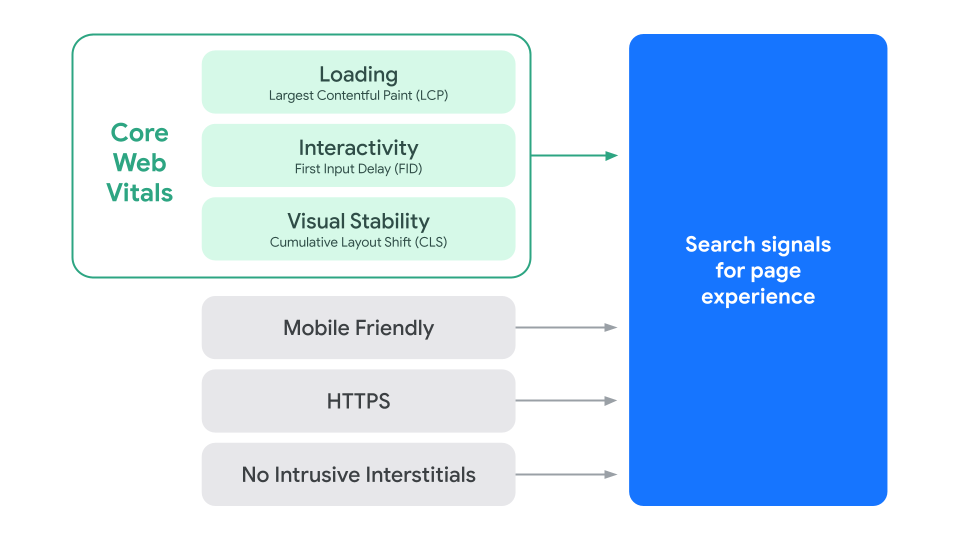
在SEO历史上,外链(Backlinks)曾被视为最强排名因素。
早期搜索算法依赖 PageRank,即:
一个网页被多少网页链接,以及这些网页的权威度。
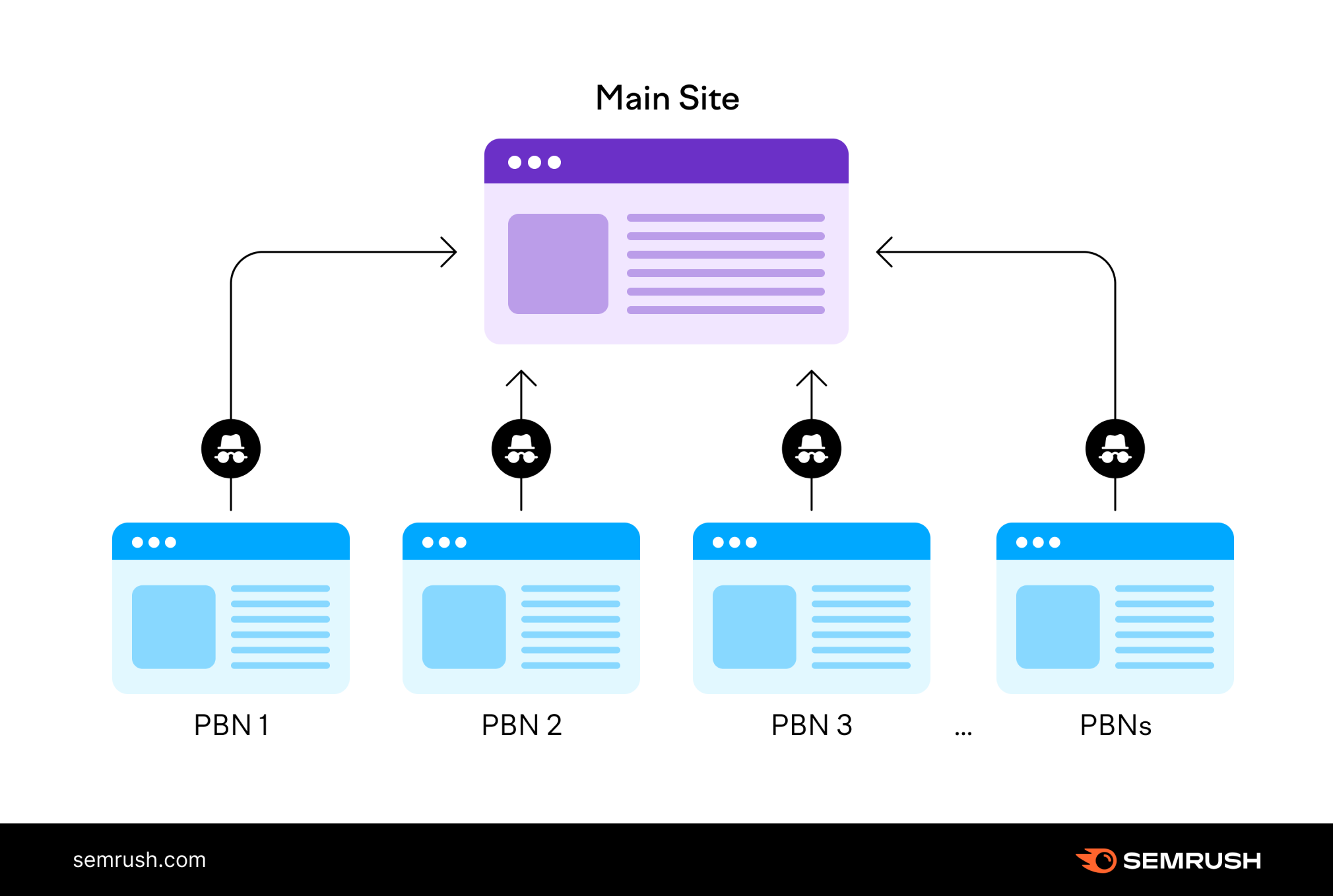
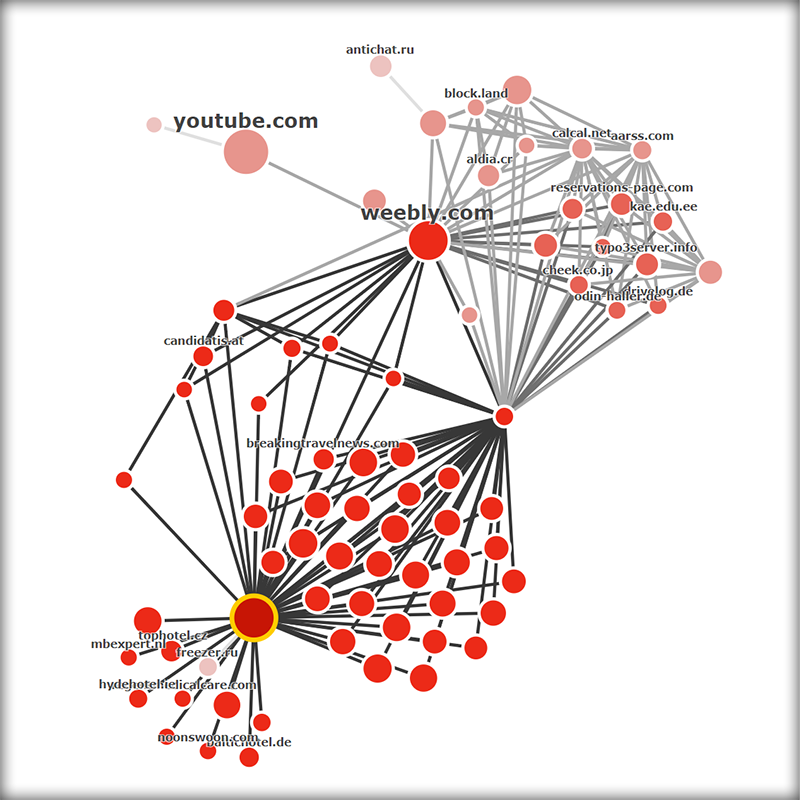
然而随着SEO行业的快速发展,大量人为操纵链接的行为出现:
在大多数SEO策略中,我们习惯思考“排名因子”。
但在Google的系统层面,它思考的是:
如何在不确定的用户意图下,最大化整体满意度?
这就是“内容多样性(Content Diversity)”存在的意义。
它不是锦上添花,而是搜索质量控制的核心机制之一。
以关键词 “jaguar” 为例。
它可以指:
在过去几年中,围绕 核心算法更新(Broad Core Updates)、Helpful Content […]