
基于算法视角的谷歌站长指南解读(四)
Google 如何识别“低质量内容”?——从系统判定逻辑到实操优化框架
在过去几年中,围绕 核心算法更新(Broad Core Updates)、Helpful Content System、以及 E-E-A-T(Experience, Expertise, Authoritativeness, Trust) 的强化,Google 对“低质量内容”的识别逻辑越来越系统化。
这已经不是简单的“字数多少”或“原创与否”的问题,而是:
你的内容是否具备真实供给价值?
是否在系统中形成可信答案能力?
是否具备不可替代性?
本文将基于算法机制拆解 Google 认定的几类低质量内容,并给出可执行的优化路径。
一、Thin Content(薄内容):不是字数少,而是价值密度低
典型场景
- 论坛用户资料页,几乎没有信息
- 电商网站数百万 SKU,但每页只有 1–2 句描述
- 大量“城市页”:北京XX服务、上海XX服务、广州XX服务……但业务并无本地差异
算法如何识别?
Google 不再单纯看字数,而是看:
- Query-Need Coverage(查询需求覆盖度)
- 信息增量 vs 语义冗余
- 页面停留与互动信号
- 是否存在大规模模板扩张特征
如果页面存在大量“语义替换型内容”,系统会识别为低增量页面。
优化实操路径
1️⃣ 计算内容价值密度
可以用三项指标评估:
- 页面是否解决完整问题链?
- 是否包含决策支持信息?
- 是否具备实际经验或数据支持?
2️⃣ 城市页处理策略
- 无本地差异 → 合并
- 有本地差异 → 增加真实案例、政策差异、物流差异
3️⃣ 电商产品页升级
- 原厂参数 → 仅基础层
- 增加使用场景
- 增加对比表
- 增加用户反馈结构化呈现
二、Unoriginal Content(非原创内容):系统可以轻易识别
包括:
- 抓取内容
- 轻度改写
- 聚合拼接
Google 通过:
- 文本指纹匹配
- 语义相似度计算
- 原始发布源权重判定
来判断“源头供给者”。
即便只有少量此类页面,也会降低整体站点评级。
优化策略
- 删除或 noindex
- 用“观点 + 经验 + 数据”重构
- 建立作者专业身份页
三、Nondifferentiated Content(无差异内容):原创但无价值增量
举例:
“How to make French toast”
在 Google 索引中已有数千页面。

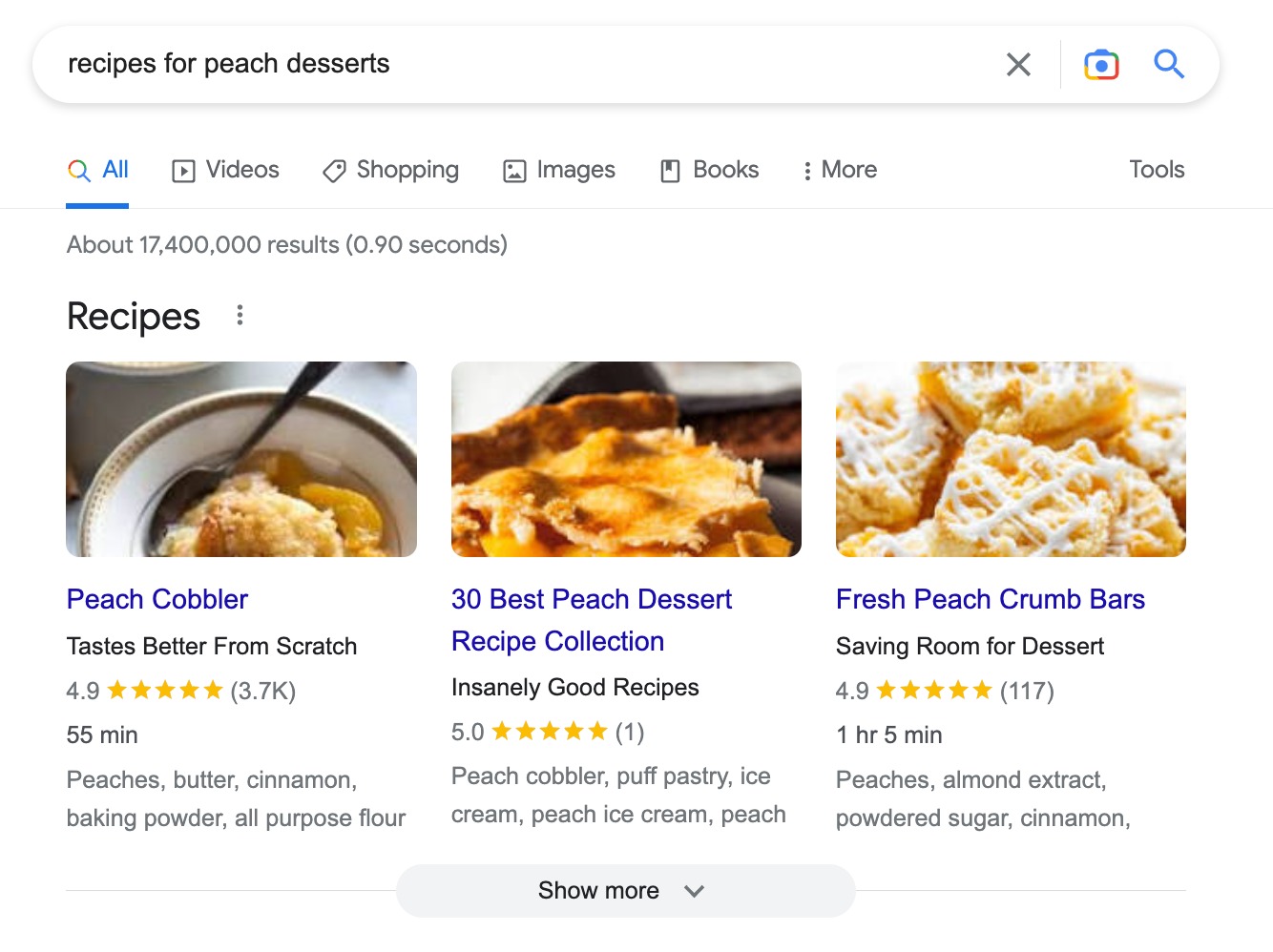
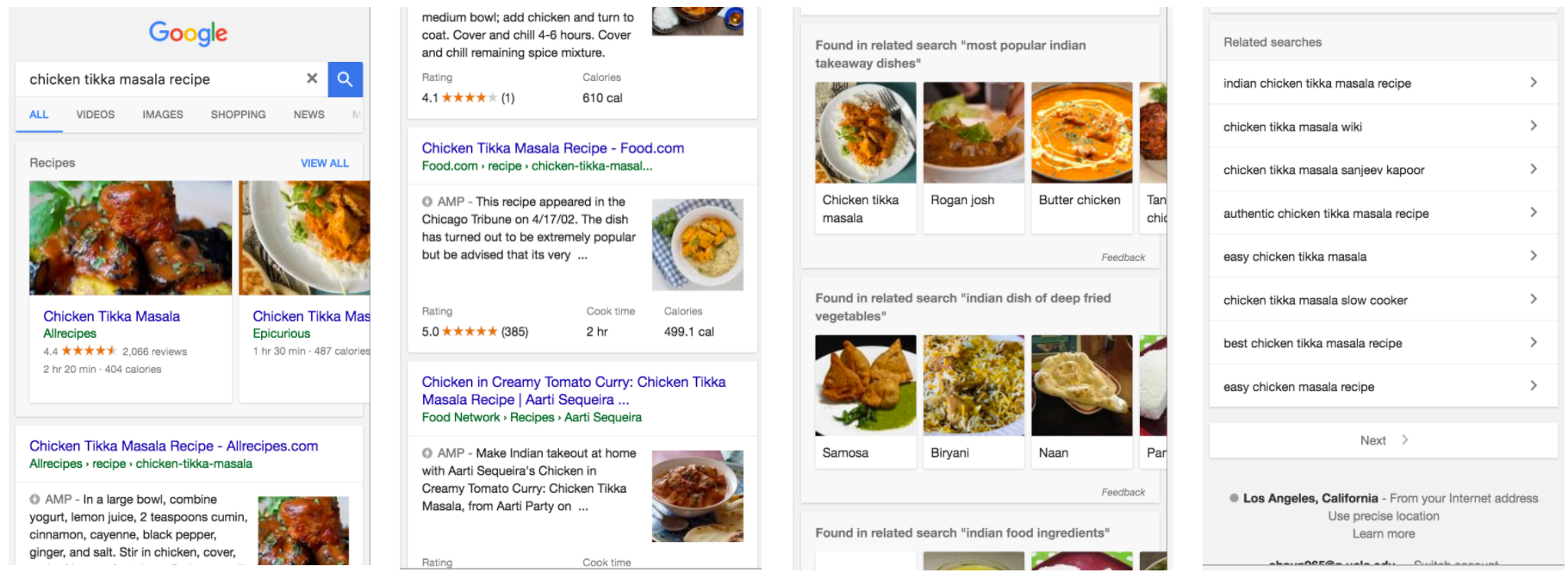
Google 的问题是:
还需要你这一篇吗?
算法核心逻辑
当某主题供给过剩时,系统会优先:
- 选择权威来源
- 选择用户信号更强页面
- 选择有独特视角的内容
实操解决方案
建立差异化矩阵
| 维度 | 举例 |
|---|---|
| 人群差异 | 糖尿病患者如何做 French Toast |
| 场景差异 | 露营版 French Toast |
| 结构差异 | 5 种失败原因解析 |
| 数据差异 | 热量对比实验 |
没有差异化,就没有排名空间。
四、Poor-quality / Inaccurate Content(低质或错误内容)
算法识别方式包括:
- 拼写与语法模型
- 事实校验系统
- 引用来源质量
- 用户反馈信号
内容如果存在事实错误,会削弱 Trust 信号。
优化建议
- 添加权威引用来源
- 标明更新时间
- 引入专业作者背书
- 建立“内容审校流程”
五、Curated Content(纯链接聚合内容)
单纯:
“10个优秀网站推荐”
然后只有链接
算法会判断为低信息密度页面。
优化方式
- 每个链接必须附带:
- 使用场景说明
- 优劣对比
- 适用人群分析
- 作者实际体验
否则建议不要发布。
六、Too-Similar Content(高度相似页面)
内容农场常见策略:
- nursing school
- nursing schools
- nursing colleges
- nursing universities
实际上语义一致。
算法识别机制
- 语义聚类
- 关键词同源归并
- Canonical 判定
- 内链结构异常检测
解决方法
- 主题聚类合并
- 建立 Pillar + Cluster 结构
- 避免关键词堆叠型页面扩张
七、Database-Generated Content(数据库生成页面)
电商网站本质是数据库生成内容,但问题在于:
- 是否仅模板生成?
- 是否缺乏人工价值补充?
Google 不反对数据库内容,但反对“规模化低价值生成”。
优化模型
数据库生成 → 基础层
人工增强 → 决策层
结构化数据 → 信号层
八、AI-Generated Content:真正的风险点在哪?
Google 在 2023 年之后明确表示:
AI 不是问题,滥用才是问题。
关键在于是否“Helpful”。
但系统仍会检测:
- 批量生成模式
- 语义模板重复
- 缺乏经验信号
- 作者不明确
风险本质
AI 内容通常是“信息整合”,
而非“经验供给”。
这直接削弱 E-E-A-T 中的:
Experience(经验)
实操建议
1️⃣ AI 仅用于:
- 结构草稿
- 内容补充
- Gap 分析
2️⃣ 必须:
- 由真实专家审稿
- 以专家名义发布
- 增加第一手经验
- 增加原创数据
3️⃣ 不可:
- 批量生成整站
- 作为主要供给来源
九、从算法系统视角总结:Google 真正在过滤什么?
低质量内容的共同特征:
- 无供给价值
- 无经验信号
- 无差异化
- 无可信背书
- 无结构清晰度
而 Google 的核心目标是:
找到“最值得被依赖的供给者”
这与你当前在研究的“系统依赖阶段”高度相关。
如果站点内容:
- 可替代
- 模板化
- 批量生成
- 无真实专业信号
那么即便没有惩罚,也会被系统边缘化。
十、实操:建立“低质量风险审计清单”
你可以建立一个内部评分表:
| 项目 | 是否存在 | 风险等级 |
|---|---|---|
| 模板城市页 | □ | 高 |
| 关键词变体扩张页 | □ | 高 |
| 纯链接聚合页 | □ | 中 |
| AI 批量内容 | □ | 高 |
| 无作者信息 | □ | 中 |
| 无更新记录 | □ | 中 |
结语:算法不是惩罚系统,而是选择系统
很多站长误以为:
“低质量 = 会被惩罚”
实际上更准确的理解是:
低质量 = 不会被选择
在供给过剩的互联网环境中,
Google 只需要最好的。
而真正的SEO策略,不是规避惩罚,
而是建立不可替代的供给能力。
最近文章
基于算法视角的谷歌站长指南解读(四) Google 如何识别“低质量内容”?——从系统判定逻辑到实操优化框架 在过去几年中,围绕 [...]
Google 2026年3月文档更新解读 “Preferred Image”最佳实践背后,是缩略图控制权的再分配 [...]
Quality Content:从 Panda 到 [...]